two point five.
disclaimer: while I may be knowledgeable in these fields, I am by no means a professional. this is NOT technical advice
the other day I was fangirling over the potential of web3 (as usual – if you follow me on twitter, you probably notice it a lot). at the time I was using my favorite decentralized service – the ipfs, a decentralized and distributed file storage system – to permanently leave a footprint of some data i had on my laptop. but soon enough I had realized some clearly obvious shortcomings of this incredible technology. before I address the main shortcoming, I think its important to understand how decentralized systems like the ipfs work on a high level.
most decentralized systems are organized in a graph network type structure where the underlying infrastructure is organized through “nodes” each representing a member of the system. for example the ipfs’s underlying infrastructure can look something like this (this is extremely simplified):
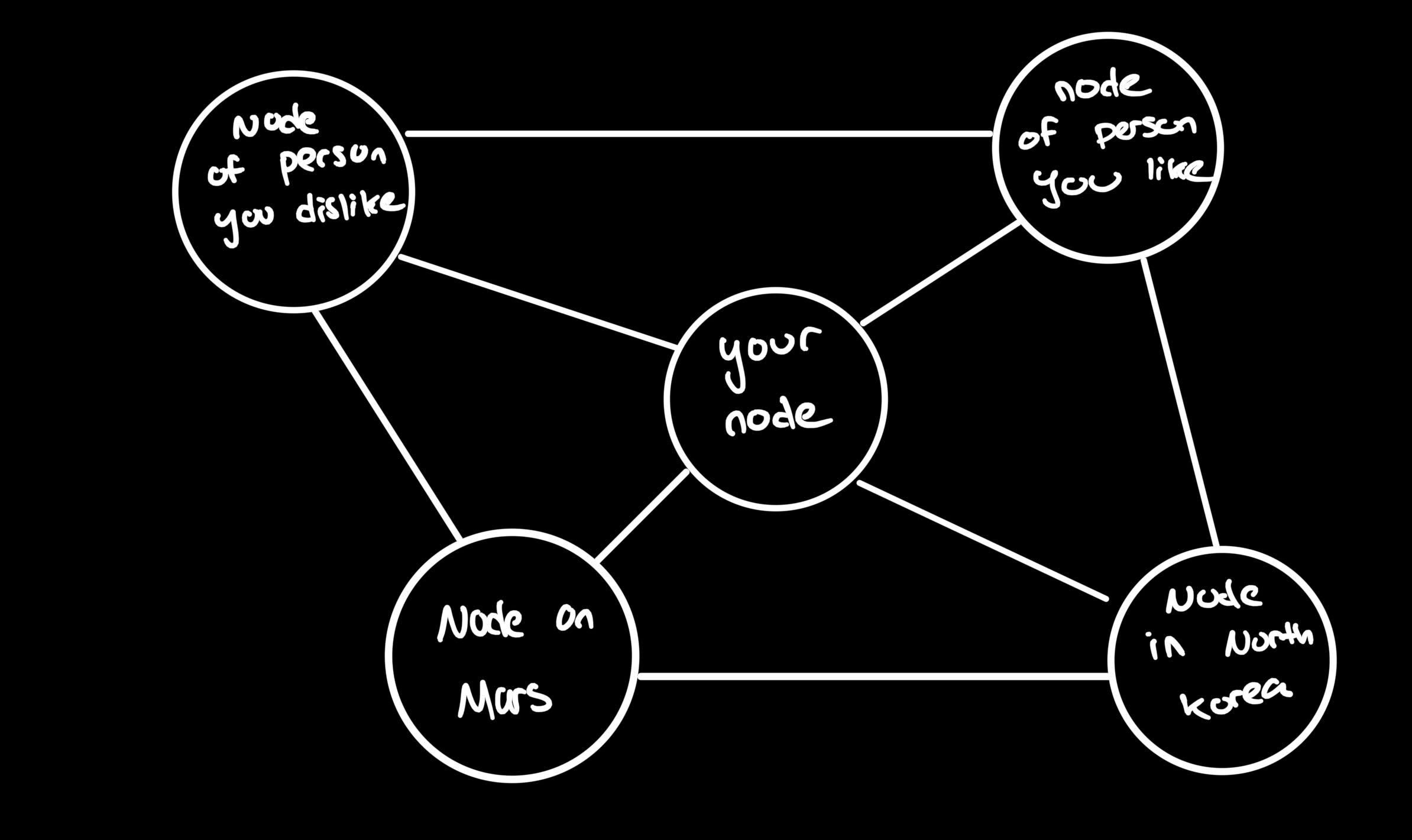
the really powerful part of this is that it is completely non-discriminatory, censorship resistant, and far more robust than traditional file systems (its really really really hard to take down the entire ipfs). there is no central entity that can stop a user from anywhere in the world regardless of beliefs, status in society, or, quite frankly, any other factor from joining the ipfs network.
this solves some of the concerns of traditional file systems. for example a web2 based file system could experience an abuse of central authorithy (which actually happens quite frequently in authoritarian governments where censorship of media is common):
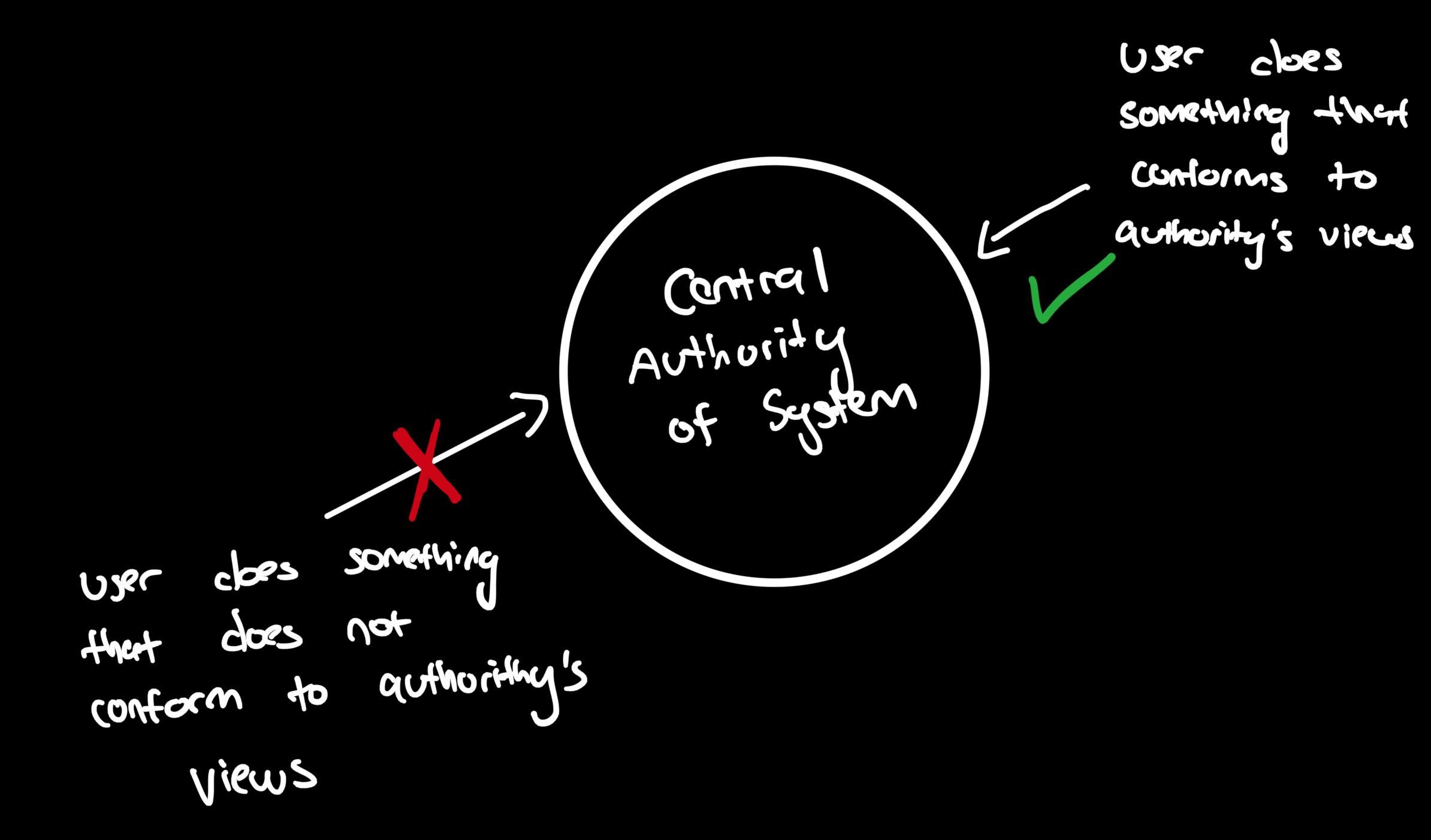
as we can see here, there is a central authority that decides what goes and what doesn’t. web3 solves this issue but at what cost?
this brings me to the what I believe is the biggest shortcoming of decentralized and distributed systems – speed. in a centralized file system, speed is not really a concern because there is only one location to get the media from. when retrieving an image from the ipfs, at times it can take several minutes to load the content. so what gives – why is it so slow? effectively how the ipfs was designed was that each node in the network would not host all the data on the ipfs. it would only host the data that was requested. and it gets requested data by querying the graph network until it finds the peer node with the data it is looking for. this makes it quite slow to get data its never retireved before and oftentimes unfeasible to use for applications that need to retrieve data quickly.
my proposed solution takes the best of the web2 and web3 systems. the idea is that we would preserve the graph network that makes web3 systems so powerful but add a different type of node that hosts a copy of all data uploaded to the graph network. (emphasis on a copy of the data because in the case that these nodes went down, we would still want to preserve the robust nature of a decentralized system). these new types of nodes would have no extra “power” or authority in the distrubuted file system.
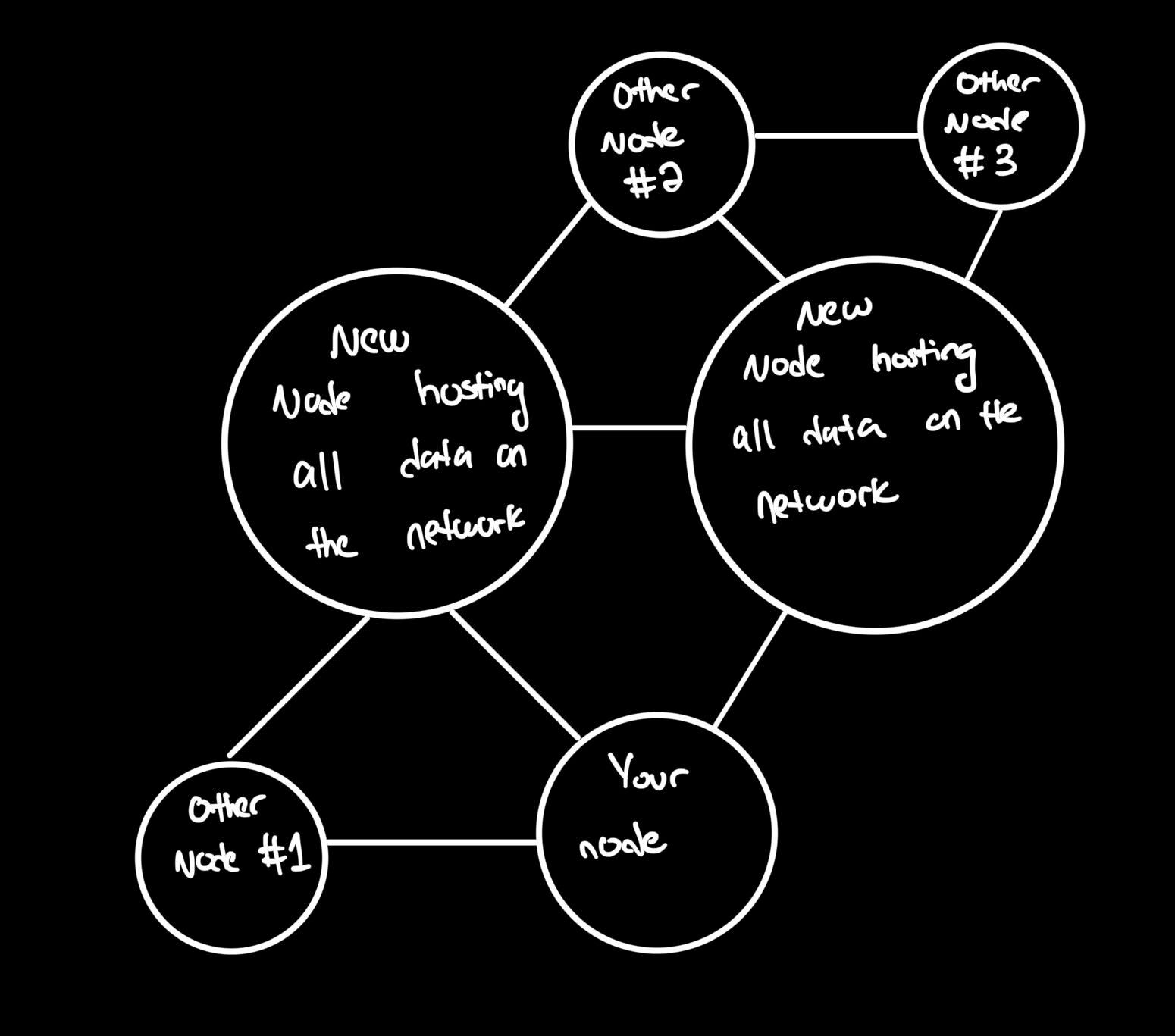
this would ensure the fast access that web2 systems provide with the censorship resistant and non-discriminatory nature of web3 systems. of course these new types of nodes would be entitled to some sort of “reward” for hosting this data but I have not had the chance to fully flesh out the economy of a system like this.
as much as I believe in an internet built on top of web3 technologies, I don’t think its a bad idea to sometimes revisit our roots and see what allowed web2 technology to thrive for the past 3 decades. sometimes these ideas may just lead to the next big innovation in web3 and this is what I believe I have found here. a still fully decentralized system that draws upon some of the best aspects of web2.
its hard for me to say if an internet on built on web2 or web3 will completely dominate but I would not be suprised if a web2.5 happens.
I can say with confidence though, a web5 system will never take over the internet :)